Příspěvek o ničem
Dnes jsem měl skoro celý den inteligenční mínus, takže mi to v práci moc nešlo, ale přežil jsem to a dokonce jsem i něco málo udělal, takže to až tak hrozný nebylo, protože nějakou činnost jsem přeci jen vyvinul.
Momentálně jsem trošku přiopilý, ale jen lehce (měl jsem dva panáčky kalvádosu — normálně to nepiju, ale dnes jsem udělal výjimku). Vzhledem k tomu, že je zítra svátek, tak si to můžu dovolit. Dnes večer navíc někam vyrazím. Ještě nevím kam, ale to není podstatné. Státní svátek se musí oslavit a jak říká heslo jedné nejmenované lihoviny "Důvod k oslavě se najde vždycky." (nebo tak nějak).
Tento příspěvek je úplně o ničem, že? :o) No ale co naděláte. Je to můj blog, tak si sem můžu psát co se mi zlíbí.
- Napsal: bobocop, 27.10.2004, 18:00:00
- Kategorie: Jen tak
- Trvalý odkaz
- Komentáře (0)
Webové standardy česky
Vít Dlouhý včera zveřejnil odkaz na překlad článku Webové standardy — více než jen beztabulkový web (autor Russ Weakley). Spolu s ním se na překladu podíleli Lukáš Mačí a David Špinar.
Ten dokument má určitě význam pro všechny, kdo to s tvorbou webu myslí alespoň trošku vážně. Přeci jen je lepší číst dokument Web standards — more than just 'table-free sites' v češtině, než v angličtině (tedy alespoň pro mě určitě). Kromě toho, že bych chtěl touto cestou poděkovat výše zmíněným lidem, tak bych si rovněž chtěl tak trošku postěžovat.
Je pěkné, že se překládají takové dokumenty, ale raději bych uvítal překlad například pro dokument Web Content Accessibility Guidelines 1.0, který se mi nepodařilo nikde na webu najít (mluvím o tom překladu). Existují sice různě upravené verze (například pravidla Blindfrienly web nebo Pravidla tvorby přístupného webu), ale pokud by se chtěl člověk při tvorbě webu držet konkrétně WCAG, tak musí umět anglicky a to já neumím. Ovšem pravdou asi bude, že většina těch napodobenin z WCAG vychází.
Malé ryby, taky ryby, takže jsem rád, za každý překlad, čehokoliv nečeského.
- Napsal: bobocop, 22.10.2004, 16:28:00
- Kategorie: Webdesign
- Trvalý odkaz
- Komentáře (0)
XHTML nebo HTML?
Toto téma včera rozvířil svým příspěvkem na serveru interval.cz Jiří Kosek a ačkoliv jsem si říkal, že se k tomu nebudu vyjadřovat, stejně jsem to porušil, tak proč se k tomu nevyjádřit i tady.
Úvod
Úvodem bych měl říct, že nejsem žádný odborník na specifikace, standardy a podobně. Neumím ani anglicky, takže veškerá "doporučení", která vydává W3C, jsou mi v podstatě k ničemu, pokud je někdo nepřevede do mě srozumitelné podoby. Sice již pracuji s počítačem víc než deset let, takže jsem se za tu dobu samozřejmě naučil rozumět některým anglicky psaným textům (alespoň na takové úrovni, abych dokázal zhruba pochopit, o co jde), ale to je tak vše.
Můj názor
Teď jen něco málo k tomu tématu. Když se člověk zamyslí nad tím, co v tom článku pan Kosek napsal, tak mu v podstatě musí dát za pravdu, ale já to vidím tak, že pokud se dá jen malým ústupkem (neuvedení xml deklarace a nastavení MIME typu na text/html) docílit toho, aby se dokument psaný v XHTML zobrazil v podstatě na jakémkoliv zařízení (včetně těch mobilních), tak není důvod k tomu, dokumenty v XHTML nepsat. Proto všechny stránky, které tvořím, se snažím dělat v XHTML 1.0 Strict.
Závěr
Když se to tak vezme, tak není důležité to, v jakém značkovacím jazyce je dokument napsán, ale jestli se zobrazí ve většině prohlížečů (včetně těch mobilních). Také je důležité to, jak je dokument napsán. Tím mám na mysli jeho strukturu (sémantiku, či jak se to nazývá) — tedy to, aby prvky, které mají být nadpisy, byly tvořeny značkami pro nadpis a ne nějakým <font size=...> atd.
No a to je asi tak všechno, co bych k tomu chtěl říct.
- Napsal: bobocop, 12.10.2004, 17:44:00
- Kategorie: Webdesign
- Trvalý odkaz
- Komentáře (2)
Data k výsledku výzkumu mobilních prohlížečů
Chtěl bych zveřejnit nějaká data, která přispěla k mému výsledku výzkumu mobilních prohlížečů.
Metodika
Postupoval jsem tak, že jsem provedl odhad nejčastěji se vyskytujících řetězců v identifikacích mobilních prohlížečů. Tím odhadem mám na mysli to, že jsem se podíval na identifikace a řetězec, který se na první pohled vyskytoval nejčastěji jsem použil. Poté jsem počítal četnosti jednotlivých řetězců a kontroloval řádky, které do výsledku nezapadly a zjistil tak další řetězce, které se daly použít.
Postupným počítáním četností výskytu těchto řetězců jsem dospěl až ke konečnému sestavení řetězce.
Graf četnosti výskytu jednotlivých řetězců — slučovací metoda
Tento graf vyjadřuje počet výskytů jednotlivých částí konečného řetězce na vzorku 5102 identifikací bez ohledu na to, jestli se již nevyskytovala některá jiná část řetězce (slučovací metoda).
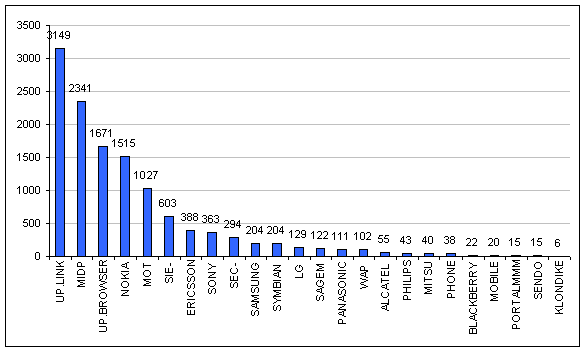
Klepnutím na obrázek můžete zobrazit jeho zvětšenou variantu.
Graf četnosti výskytu jednotlivých řetězců — vylučovací metoda
Tento graf vyjadřuje počet výskytů jednotlivých řetezců po aplikaci vylučovací metody, která spočívala v několikanásobném (přibližně čtyřnásobném) procházení řetězců seřazených podle počtu jejich výskytu a nezapočítání jejich výskytu, pokud se již vyskytl některý řetězec s vyšším počtem výskytů (vylučovací metoda).
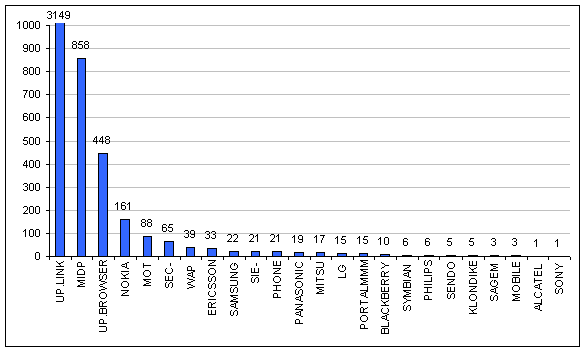
Klepnutím na obrázek můžete zobrazit jeho zvětšenou variantu.
- Napsal: bobocop, 3.10.2004, 18:51:29
- Kategorie: Webdesign
- Trvalý odkaz
- Komentáře (0)
Aktualizace funkce IsMobile
Dnes jsem vystavil aktualizaci funkce IsMobile, která slouží k identifikaci mobilních prohlížečů.
Byl jsem upozorněn na to, že se dá funkce zjednodušit prostřednictvím regulárních výrazů, tak jsem se podíval do chytré knížky o PHP, nastudoval si o nich hrubé základy a funkci jsem upravil, takže se nejen zmenšila, ale s největší pravděpodobností i zrychlila.
- Napsal: bobocop, 2.10.2004, 19:41:00
- Kategorie: Webdesign
- Trvalý odkaz
- Komentáře (0)
Archivy
- červenec 2011
- červen 2011
- květen 2011
- únor 2011
- červenec 2010
- červen 2010
- duben 2010
- březen 2010
- únor 2010
- leden 2010
- listopad 2009
- říjen 2009
- září 2009
- červen 2009
- březen 2009
- prosinec 2008
- listopad 2008
- říjen 2008
- srpen 2008
- červen 2008
- květen 2008
- duben 2008
- březen 2008
- únor 2008
- prosinec 2007
- listopad 2007
- září 2007
- červen 2007
- květen 2007
- duben 2007
- březen 2007
- leden 2007
- prosinec 2006
- říjen 2006
- září 2006
- srpen 2006
- červenec 2006
- červen 2006
- duben 2006
- březen 2006
- únor 2006
- leden 2006
- prosinec 2005
- listopad 2005
- říjen 2005
- září 2005
- srpen 2005
- červenec 2005
- červen 2005
- květen 2005
- duben 2005
- březen 2005
- únor 2005
- leden 2005
- prosinec 2004
- listopad 2004
- říjen 2004
- září 2004
- srpen 2004
- červenec 2004
- červen 2004
Odkazy
- Bohumír Bednařík
- Matějka Koupelny
- Škola pro výcvik vodicích psů pro nevidomé
- Básničky.cz
- Veřejný weblog
- Montáže nábytku
Ostatní
Vyhledávání
Reklama
![]()
![]()